
はじめに
plot_importanceを用い、分類予測時における特徴量重要度を求め特徴量の選定を行う。
今回も前回の記事で用いたSIGNATEに記載されている【練習問題】ガラスの分類(https://signate.jp/competitions/125)を使用しています。
前回記事のソースコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd from sklearn.model_selection import train_test_split import lightgbm as lgb from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score df = pd.read_table('./data/train.tsv') x = df[["RI", "Na", "Mg", "Al", "Si", "K", "Ca", "Ba", "Fe"]] y = df["Type"] X_train, X_test, Y_train, Y_test = train_test_split(x, y, random_state=0) lgbm = lgb.LGBMClassifier() lgbm.fit(X_train, Y_train) Y_pred = lgbm.predict(X_test) print(f"正解率:{accuracy_score(Y_test,Y_pred)}") print(f"適合率:{precision_score(Y_test,Y_pred, average=None)}") print(f"再現率:{recall_score(Y_test,Y_pred, average=None)}") print(f"F1値:{f1_score(Y_test,Y_pred, average=None)}") |
特徴量重要度の表示
|
1 |
lgb.plot_importance(lgbm) |
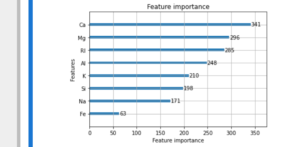
今回のモデルにおける上位4つの特徴量を使用し, 再度モデルの構築を行い予測を行っていきます。
モデル構築~評価
|
1 2 3 4 5 6 7 8 9 10 |
x2 = df[["Ca", "Mg", "RI", "Al"]] y2 = df["Type"] X2_train, X2_test, Y2_train, Y2_test = train_test_split(x2, y2, random_state=0) lgbm2 = lgb.LGBMClassifier() lgbm2.fit(X2_train, Y2_train) Y2_pred = lgbm2.predict(X2_test) print(f"正解率:{accuracy_score(Y2_test,Y2_pred)}") print(f"適合率:{precision_score(Y2_test,Y2_pred, average=None)}") print(f"再現率:{recall_score(Y2_test,Y2_pred, average=None)}") print(f"F1値:{f1_score(Y2_test,Y2_pred, average=None)}") |
|
1 2 3 4 |
正解率:0.6666666666666666 適合率:[1.0, 0.5625, 0.0, 0.0 ,1.0 , 0.0 ] 再現率:[0.72727273, 0.9, 0.0, 0.0, 0.33333333, 0.0] F1値:[0.84210526, 0.69230769, 0.0, 0.0, 0.5, 0.0] |
特徴量を減らしたことによって複雑なモデルではなくなってしまっため全体的に数値が低くなってしまっている。
提出用ファイルの作成
|
1 2 3 4 5 6 |
df_test = pd.read_table('./data/test.tsv') x_test = df_test[["Ca", "Mg", "RI", "Al"]] pred = lgbm2.predict(x_test) df_test["Type"] = pred df_test["id"] = df_test["Unnamed: 0"] df_test[["id", "Type"]].to_csv("submit_test_lgbm0508_1.csv", header=False, index=False) |
今回のモデルで予測を行い提出をしたところ正解率0.7102804と過学習が起きず前回のモデルに比べ, 汎用性の高いモデルが構築できた。
※今回提出ファイルを提出する際にデータを分割せず, 再度モデルの構築を行っていいるため上記のソースコードと異なる部分があります。